| ||||||||||||||||||||||||||||||||||||||||||||||||||||||

| ||||||||||||||||||||||||||||||||||||||||||||||||||||||
Supercomputers and changing times
A supercomputer is a computer at the frontline of contemporary processing capacity particularly speed of calculation which can happen at speeds of nanoseconds.
Supercomputers play an important role in the field of computational science, and are used for a wide range of computationally intensive tasks in various fields, including quantum mechanics, weather forecasting, climate research, oil and gas exploration, molecular modeling (computing the structures and properties of chemical compounds, biological macromolecules, polymers, and crystals), and physical simulations (such as simulations of the early moments of the universe, airplane and spacecraft aerodynamics, the detonation of nuclear weapons, and nuclear fusion).
Supercomputing, in the broadest sense, is about finding the perfect combination of speed and power, even as the definition of perfection changes as technology advances. But the single biggest challenge in high-performance computing (HPC) is now on the software side: Creating code that can keep up with the processors.
The history of supercomputing goes back to the 1960s .During those days the main idea was to use innovative designs and parallelism to achieve superior computational peak performance. While the supercomputers of the 1980s used only a few processors, in the 1990s, machines with thousands of processors began to appear both in the United States and in Japan, setting new computational performance records. Moore's Law is a famous "rule" of computer science which states that processing power will double every 1.5-2 years and it has held true for over 50 years. By the end of the 20th century, massively parallel supercomputers with thousands of "off-the-shelf" processors similar to those found in personal computers were constructed and broke through the teraflop computational barrier. Progress in the first decade of the 21st century was dramatic and supercomputers with over 60,000 processors have appeared.
Here is the performance of the fastest supercomputer in the world, the past 15 years:
· Top in 2010: 2.57 petaflops
· Top in 2005: 280.6 teraflops
· Top in 2000: 4.94 teraflops
· Top in 1995: 170 gigaflops
One of the challenges to faster supercomputers is designing an operating system capable of handling that many calculations per second.Other important trends which can be identified include emphasis on having open, rather than proprietary, systems, and the growing awareness of energy efficiency as a requirement.
According to top scientists emphasis is shifting a little away from the speed/power paradigm and toward addressing software challenges. "What matters is not acquiring the iron, but being able to run code that matters". Rather than increasing the push to parallelize codes, the effort is on efficient use of codes.
Sources:
http://en.wikipedia.org/wiki/History_of_supercomputing
http://royal.pingdom.com/2010/12/02/incredible-growth-supercomputing-performance-1995-2010/
Varun Singla 363/CO/11
HOW DOES INTERNET WORK
Internet is a global system of interconnected computer networks that use the standard Internet protocol suite (TCP/IP) to link several billion devices worldwide. It is a networks of networks that consists of millions of private, public, academic, business, and government networks, of local to global scope, that are linked by a broad array of electronic, wireless, and optical networking technologies. The Internet carries an extensive range of information resources and services.
Internet is a global network of computers each computer connected to the Internet must have a unique address. Internet addresses are in the form nnn.nnn.nnn.nnn where nnn must be a number from 0 - 255. This address is known as an IP address.
The picture below illustrates two computers connected to the Internet; our computer with IP address 1.2.3.4 and another computer with IP address 5.6.7.8. The Internet is represented as an abstract object in-between.

| Diagram 1 |
If we connect to the Internet through an Internet Service Provider (ISP), we are usually assigned a temporary IP address for the duration of our dial-in session. If we connect to the Internet from a local area network (LAN) our computer might have a permanent IP address or it might obtain a temporary one from a DHCP (Dynamic Host Configuration Protocol) server. In any case, if we are connected to the Internet, our computer has a unique IP address.
Servers are where most of the information on the internet "lives". These are specialised computers which store information, share information with other servers, and make this information available to the general public.
Browsers are what people use to access the World Wide Web from any standard computer.
When we connect our computer to the internet, we are connecting to a special type of server which is provided and operated by our Internet Service Provider (ISP). The job of this "ISP Server" is to provide the link between our browser and the rest of the internet. A single ISP server handles the internet connections of many individual browsers - there may be thousands of other people connected to the same server that we are connected to right now.
The picture below show a slightly larger slice of the internet:


The ISP maintains a pool of modems for their dial-in customers. This is managed by some form of computer which controls data flow from the modem pool to a backbone or dedicated line router. This setup may be referred to as a port server, as it 'serves' access to the network. Billing and usage information is usually collected here as well.
After our packets traverse the phone network and ISP's local equipment, they are routed onto the ISP's backbone or a backbone the ISP buys bandwidth from. From here the packets will usually journey through several routers and over several backbones, dedicated lines, and other networks until they find their destination.
The information used to get packets to their destinations are contained in routing tables kept by each router connected to the Internet.
Routers are packet switches. A router is usually connected between networks to route packets between them. Each router knows about it's sub-networks and which IP addresses they use.
INTERNET PROTOCOL
TCP/IP is the basic communication language or protocol of the Internet. It can also be used as a communications protocol in a private network (either an intranet or an extranet). When we are set up with direct access to the Internet, computer is provided with a copy of the TCP/IP program just as every other computer that we may send messages to or get information from also has a copy of TCP/IP.
TCP/IP is a two-layer program. The higher layer, Transmission Control Protocol, manages the assembling of a message or file into smaller packets that are transmitted over the Internet and received by a TCP layer that reassembles the packets into the original message. The lower layer, Internet Protocol, handles the address part of each packet so that it gets to the right destination. Each gateway computer on the network checks this address to see where to forward the message. Even though some packets from the same message are routed differently than others, they'll be reassembled at the destination.
http://www.mediacollege.com/internet/intro/thewww2.html
http://en.wikipedia.org/wiki/Internet
http://www.stanford.edu/class/msande91si/www-spr04/readings/week1/InternetWhitepaper.htm
http://searchnetworking.techtarget.com/definition/TCP-IP
Varun Singla 363/CO/11
CACHE COHERENCE AND SNOOPY BUS PROTOCOL
In computing, cache coherence refers to the consistency of data stored in local caches of a shared resource. When clients in a system maintain caches of a common memory resource, problems may arise with inconsistent data. This is particularly true of CPUs in a multiprocessing system. In a memory hierarchy for a multiprocessor system, data inconsistency may occur between adjacent levels or within the same level. For example, the cache and main memory may contain inconsistent copies of the same memory block because multiple processors operate asynchronously and independently. When multiple processors maintain locally cached copies of a unique shared-memory location, any local modification of the location can result in a globally inconsistent view of memory. Cache coherence schemes prevent this problem by maintaining a uniform state for each cached blocks of data.
SNOOPY BUS PROTOCOL
In computing a snoopy cache is a type of memory cache that performs bus sniffing. Such caches are used in systems where many processors or computers share the same memory and each have their own cache. Snoopy protocols achieve data consistency among the caches and shared memory through a bus watching mechanism.
There are 2 basic approaches
1. write-invalidate – invalidate all other cached copies of a data object when the local cached copy is modified (invalidated items are sometimes called "dirty")
2. write-update – broadcast a modified value of a data object to all other caches at the time of modification
Snoopy bus protocols achieve consistency among caches and shared primary memory by requiring the bus interfaces of processors to watch the bus for indications that require updating or invalidating locally cached objects
Cache consistency by bus watching mechanism

Initial state consistent caches

After Write-Invalidate by P1

After Write-Update by P1
Sources:
http://www.risc.jku.at/education/courses/ws97/intropar/architectures/index_5.html
http://www.icsa.inf.ed.ac.uk/research/groups/hase/models/coherence/
http://www.info425.ece.mcgill.ca/lectures/L28-SnoopyCoherence.pdf
Varun Singla 363/CO/11
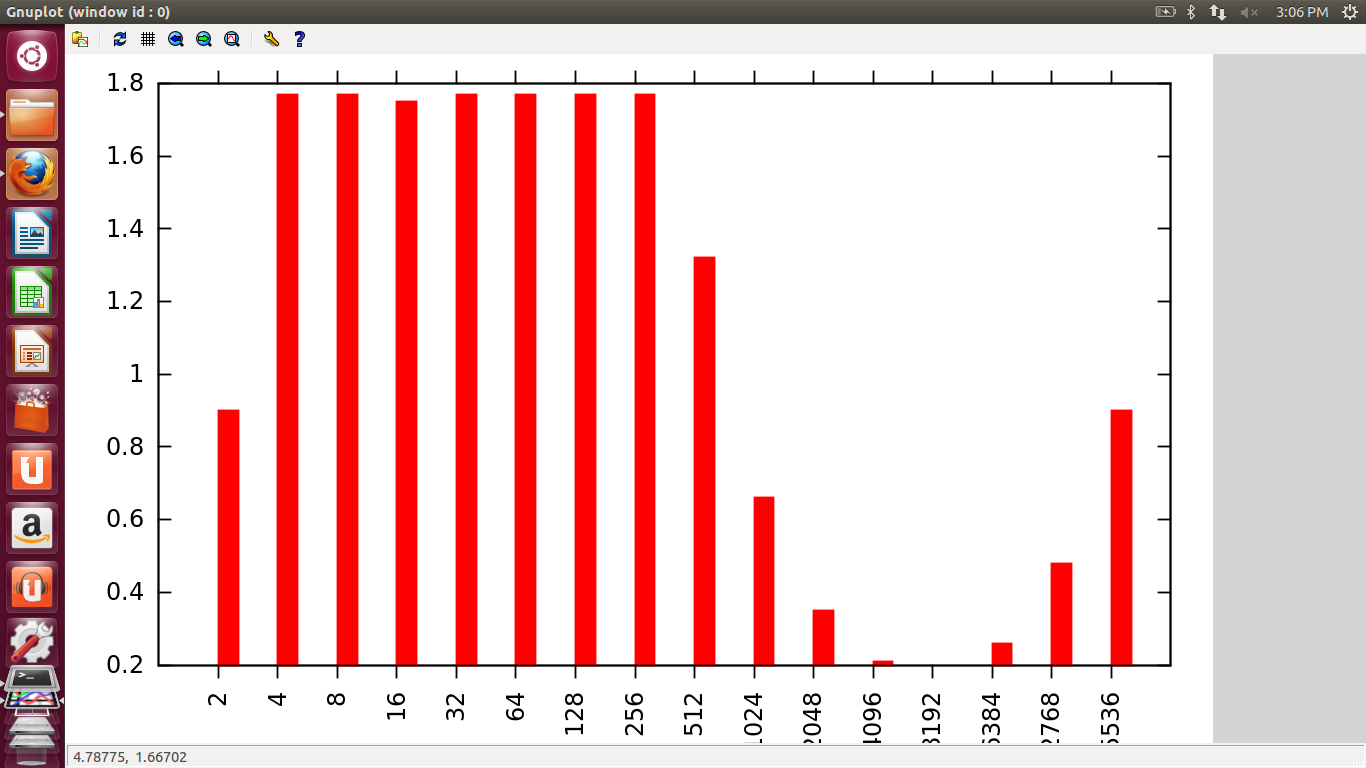
1. Pi Mutex
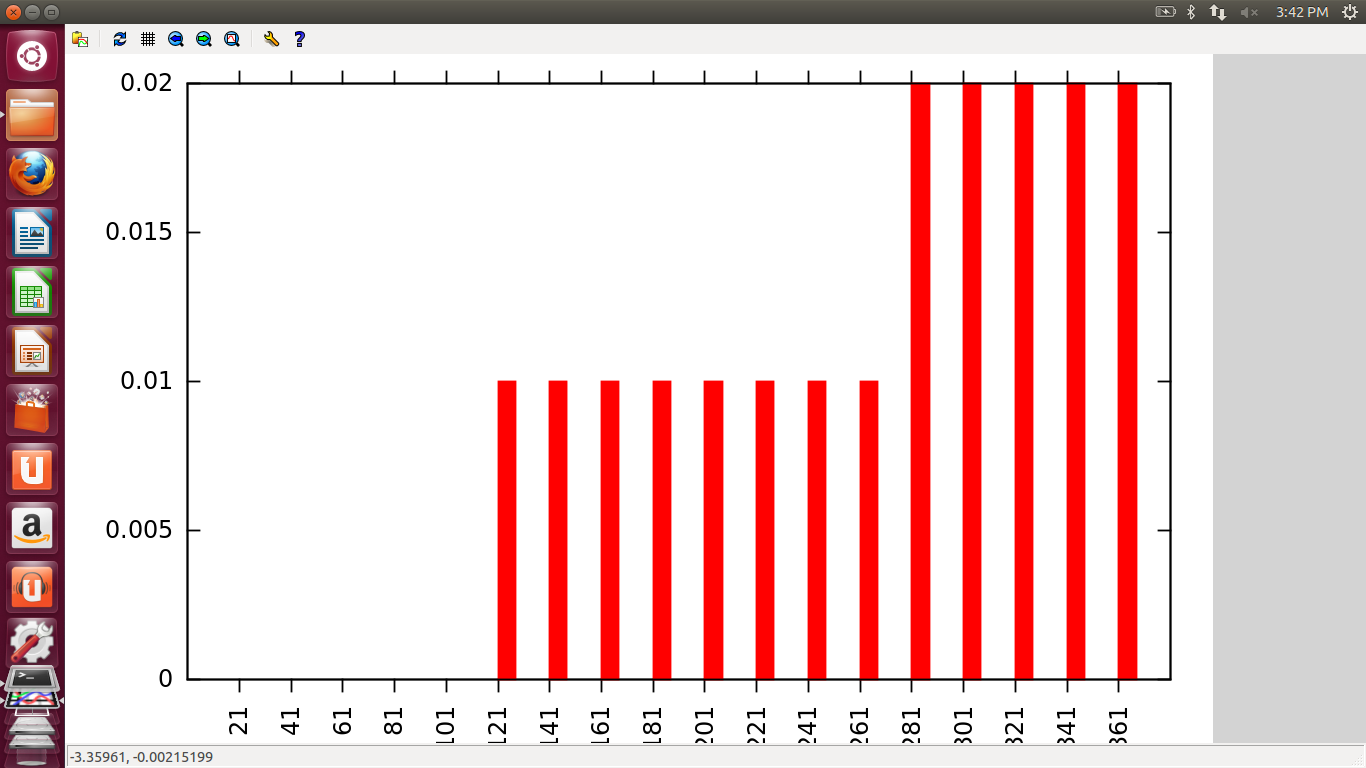
In this graph, initially time increases as number of threads increases, but eventually time decreases as number of threads increase because as we increase the number of threads work is divided and so time of execution decreases and at one point almost becomes zero or minimum because at this point equal work is done by all threads and there are minimum overheads. This is the optimum value of number of threads. But then after this, the graph gradually increases because now the work is less but the number of threads is quite large which results in increased overheads and hence increases the time of execution.
2. Pi Busywait
Here, time increases as number of threads increase as every thread is looping in an infinite loop. So as number of threads increases number of cpu cycles increases which increases the overall time.
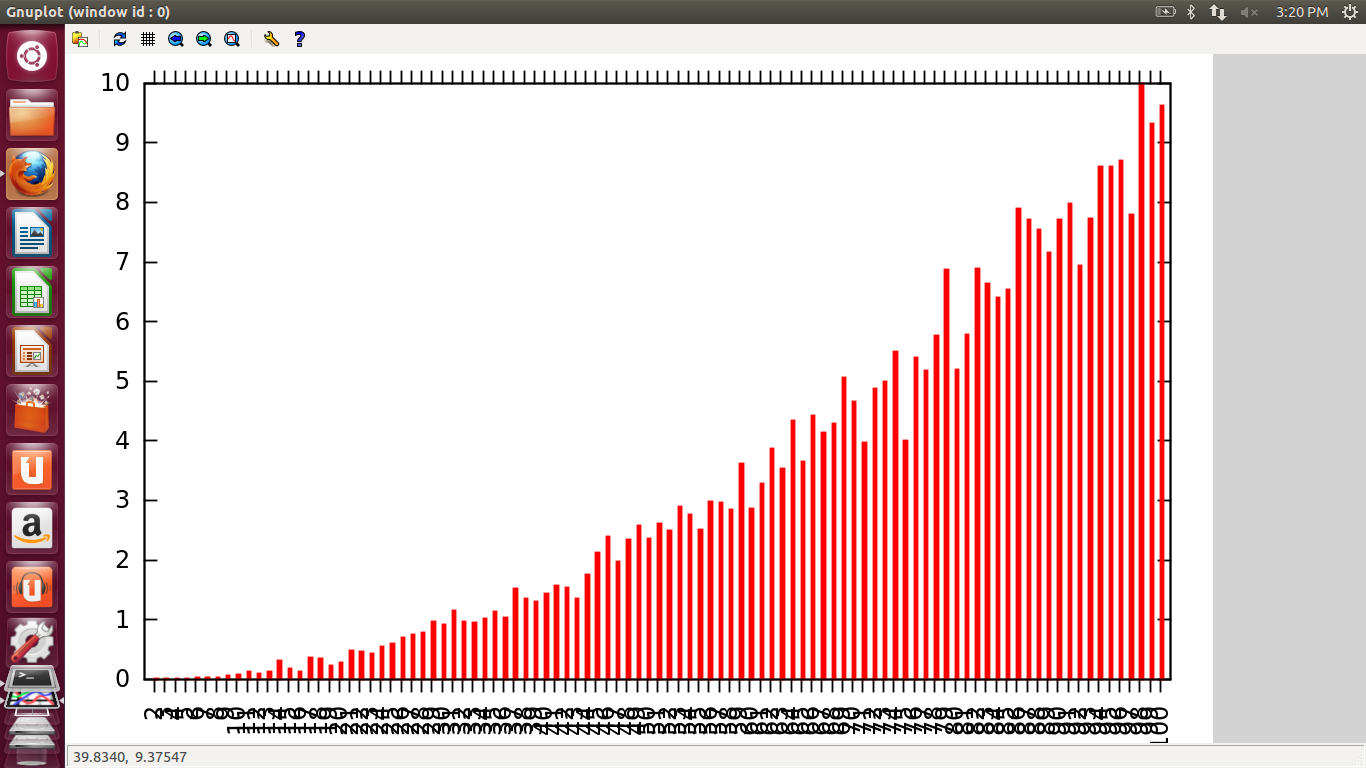
3. Matrix Multiplication
Here, when size of array is small, as the no of threads increase, the time rise is very steep because there is no point in parallelizing such small work. Overheads are more in this case.
When we increase the size of array to a high value, d graph does not rise as fast as was the case before because now each thread is working in parallel n work is distributed equally among all so time of execution is less. But when number of threads is more than what is required time increases because of overheads.
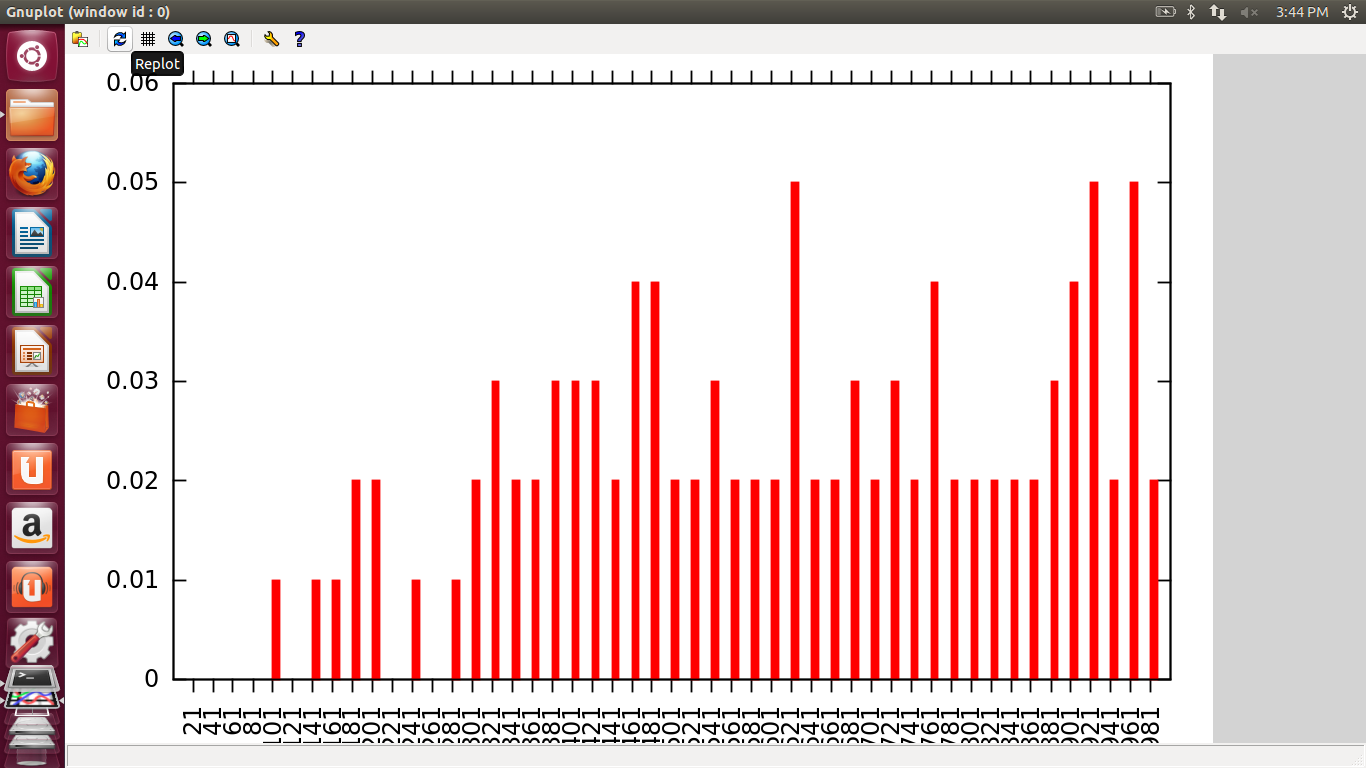
4. Barrier Semaphores
Here, graph could not be seen properly because number of threads could not be increased after a certain point because OS would not allow it. So the actual graph could not be obtained but it was seen that for very few number of threads time was almost zero n at high values of no. of threads time increases to a great extent.
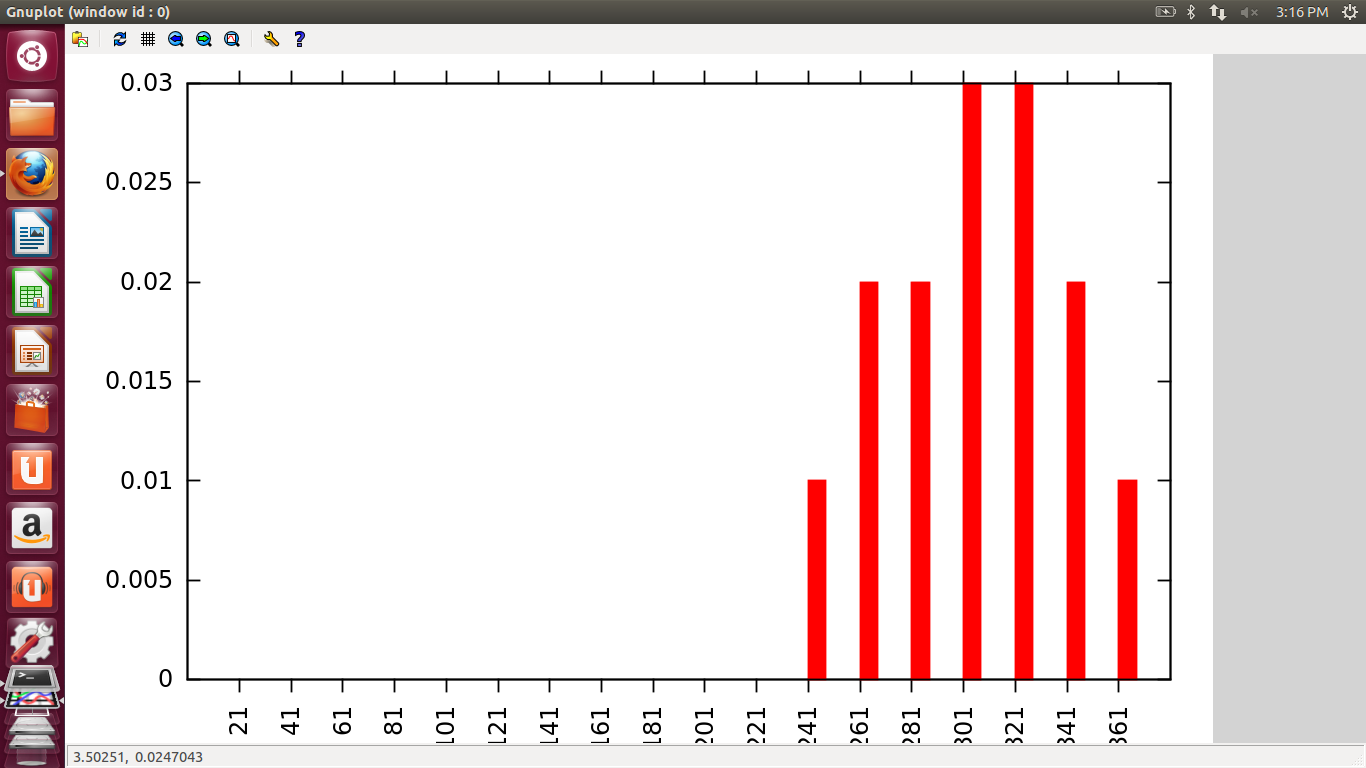
5. Barrier Mutex
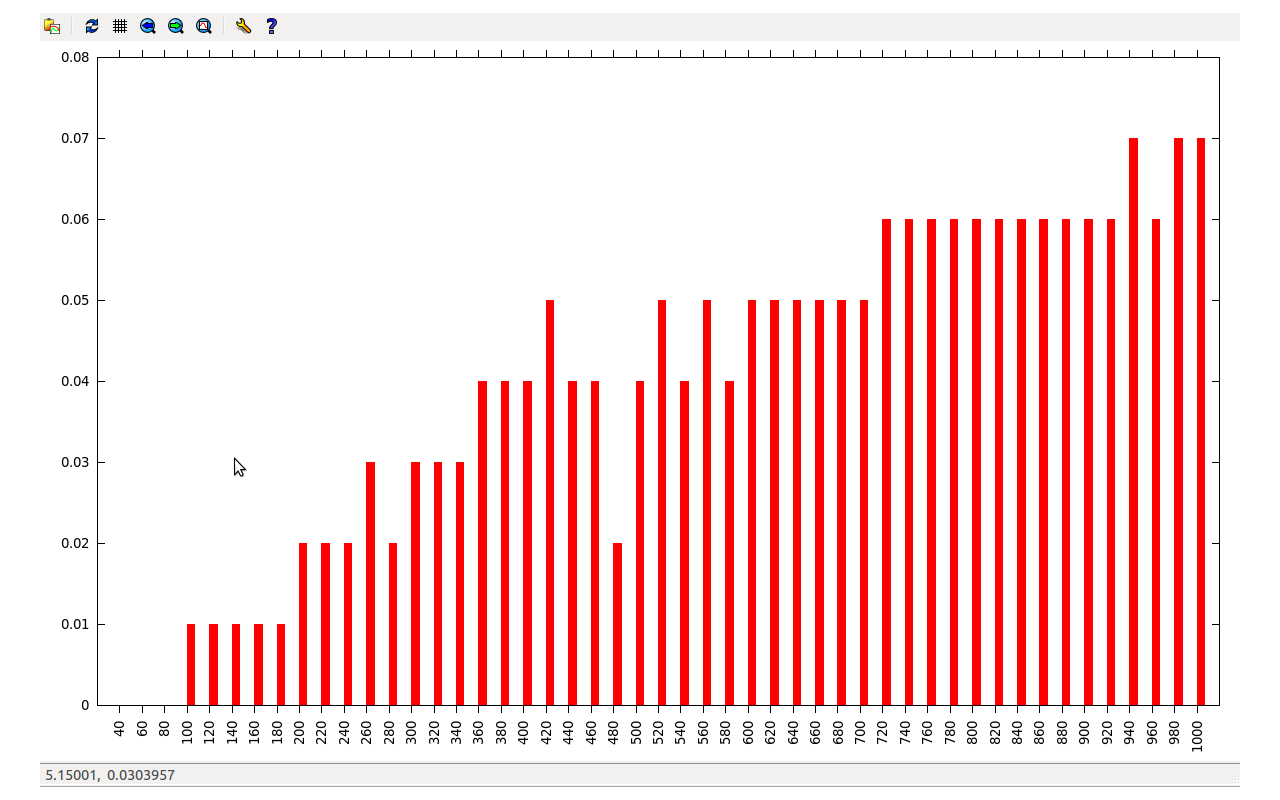
Here, the graph increases linearly with the number of threads.
6. Conditional Barrier
Here also, graph could not be seen properly because number of threads could not be increased after a certain point because OS would not allow it. So the actual graph could not be obtained. But it was seen that for very few number of threads time was almost zero and at high values of number of threads time increases to a great extent.
7. Cout v/s Std
Here, the graphs just show that std is faster that cout.
VIVEK SEHGAL 374/CO/11
VIREN GULATI 369/CO/11
This blog talks about the basics of the PRAM model and its variants. We would also be discussing a very important algorithm dealing with locating the greatest entry in an array using parallel processing.
PRAM models are classified on the basis of the methods employed in handling the various conflicts, and the speed at which they can solve problems. Hence the variants of PRAM model are:-
1. Exclusive Read Exclusive Write (EREW)
2. Exclusive Read Concurrent Write (ERCW)
3. Concurrent Read Exclusive Write (CREW)
4. Concurrent Read Concurrent Write (CRCW)
Here we would be focussing on the CRCW model only. Since multiple processors are interacting and accessing the memory at the same time, conflicts would be inevitable. In case of reading the memory at the same time, no conflicts would be expected because the processors need not enter the critical section when they are only reading concurrently. One way of achieving this would be making use of broadcasting, as do the crossbar and multistage networks. Here the broadcaster sends the duplicated value to the shared memory and these values can then be read by the processors. But in the case of concurrent write, since more than one processor try to access the memory and write into the same memory location at the same time, conflicts are unavoidable and the need for algorithms to tackle these conflicts arises.
Now let's talk about the algorithm which employs parallel processing to locate the element with the greatest value in an array. We would be inputting an array s[ ] from the user, which is the array in which the element with the maximum value is to be located. Since this algorithm makes use of parallel processing, it is way faster than the other methods, but the space complexity increases because of the use of nC2 processors. We are using nC2 processors because we need one processor per comparison and because the elements are being compared in pairs. For example, the processor p[1,2] compares the the values of the first and the second elements. We would also be using another array t[ ] to store locate the element we are searching for. In this array, the entry '1' for an element means that it hasn't been eliminated and '0' means that it has been eliminated and that it cannot be the element having the greatest value. For example, when the processor p[1,2] is done comparing the first two elements, the entry in t[ ] corresponding to the element with the lower value is changed to 0. Likewise, the entry in t[ ] corresponding to the element with the greater value is changed to 1.
The values of all the entries of t[ ] are calculated in a similar fashion and at the last stage of the algorithm, we are left with an array in which all the entries are 0 apart from the one we had planned on locating. Hence the algorithm can be summarized as follows :-
1. Reading the values from the input array
2. Comparing the values in pairs
3. Changing the values of the array t[] in the manner explained above.
4. Reading the array finally obtained to locate the element whose whose value is 1.
Algorithm :-
Keytype parlargest( int n, keytype s [ ])
{
int t[n];
initialization stage- change all t[i] to 1;
local index i, j;
local keytype first, second;
local int ch1, ch2;
i= first index of processor and j= second index of processor;
Read s[i] into first and s[j] into second;
Compare both,
if(1st<2nd)
t[i]=0;
else
t[j]=1;
Read t[i] into check 1 and t[j] into check 2;
Finally, if(t[i]==1)
output s[i];
else if( t[j]==1)
output s[j];
}
VIVEK SEHGAL 374/CO/11
VIREN GULATI 369/CO/11
Inter-process communication
Inter-process communication (IPC) is a set of methods for the exchange of data among multiple threads in one or more processes. Processes may be running on one or more computers connected by a network. IPC methods are divided into methods for message passing, synchronization, shared memory, and remote procedure calls (RPC). The method of IPC used may vary based on the bandwidth and latency of communication between the threads, and the type of data being communicated.
Typically, applications can use IPC categorized as clients or servers. A client is an application or a process that requests a service from some other application or process. A server is an application or a process that responds to a client request. Many applications act as both a client and a server, depending on the situation.
There are two types of IPCs:
· LPC (local procedure call) LPCs are used in multitasking operating systems to allow concurrently running tasks to talk to one another. They can share memory spaces, synchronize tasks, and send messages to one another.
· RPC (remote procedure call) RPCs are similar to the LPC but work over networks. RPCs provide mechanisms that clients use to communicate requests for services to another network-attached system such as a server. If you think of a client/server application as a program that has been split between front-end and back-end systems, the RPC can be viewed as the component that reintegrates them over the network. RPCs are sometimes called coupling mechanisms.
Various methods for inter-process communication used in most processors
· Signals:
They are used to signal asynchronous events to one or more processes. A signal could be generated by a keyboard interrupt or an error condition such as the process attempting to access a non-existent location in its virtual memory.
· Sockets
Sockets are end points of inter-process communication flow across a network. Since communication between most computers is based on internet protocol, therefore most network sockets are internet sockets.
Sources: http://en.wikipedia.org/wiki/Inter-process_communication
http://www.linktionary.com/i/ipc.html
By- Tarun Kumar
:
MESSAGE PASSING MECHANISMS
Message passing in any multicomputer computer network requires hardware and software support. There are both deterministic and adaptive routing algorithms for achieving deadlock-free message routing.
Message Formats:
Message is a logical unit for internode communication. It is assembled from an arbitrary number of fixed length packets.
Packet: It is the basic unit containing the destination address for routing purposes. A sequence number is needed in each packet as they may arrive asynchronously to allow message to be reassembled properly. A packet can further divided into a number of fixed-length flits(flow control digits). Routing information and sequence number occupy the header flits. The remaining flits length is often affected by the network size.
WORMHOLE ROUTING

source:http://pages.cs.wisc.edu/~tvrdik/7/html/Section7.html
Wormhole switching of a packet
(a) The header is copied in the output buffer after having done routing decision. (b) The header flit is transfered to the second router and other flits are following it. (c) The header flit arrived into a router with busy output channel and the whole chain of flits along the path got stalled, blocking all its channels. (d) Pipeline of flits in case of conflict-free routing, establishing the wormhole across routers.
By- Tarun Kumar
VERY LONG INSTRUCTION WORD (VLIW)
ARCHITECTURE
Very long instruction word or VLIW refers to a CPU architecture designed to take advantage of instruction level parallelism (ILP). The VLIW approach, on the other hand, executes operations in parallel based on a fixed schedule determined when programs are compiled. Since determining the order of execution of operations (including which operations can execute simultaneously) is handled by the compiler, the processor does not need the scheduling hardware. As a result, VLIW CPUs offer significant computational power with less hardware complexity (but greater compiler complexity) than is associated with most superscalar CPUs.
Comparison of cisc,risc and vliw

Source: http://www.site.uottawa.ca/~mbolic/elg6158/vliw1.ppt
The VLIW architecture is generalized from two well-established concepts: Horizontal micro coding and superscalar processing. A typical VLIW (very long instruction word) machine has instruction words hundreds of bits in length. As illustrated in the Figure-1, multiple functional units are used concurrently in a VLIW processor. All functional units share the use of a common large register file. The operations to be simultaneously executed by the functional units are synchronized in VLIW instruction, say, 256 or 1024 bits per instruction word, as implemented in the Multiflow computer models.

Fig-1, A typical VLIW processor and instruction format
Source: http://www.csbdu.in/virtual/DIGITAL%20MUP/5.3.php
Different fields of the long instruction word carry the opcodes to be dispatched to different functional units. Programs written in conventional short instruction words must be compacted together to form VLIW instructions and code compaction must be done by compiler .
Sources: Advanced computer architecture by Kai hwang
http://en.wikipedia.org/wiki/Very_long_instruction_word
http://www.csbdu.in/virtual/DIGITAL%20MUP/5.3.php
http://www.site.uottawa.ca/~mbolic/elg6158/vliw1.ppt
By- Tarun Kumar
VERY LONG INSTRUCTION WORD (VLIW)
ARCHITECTURE
Very long instruction word or VLIW refers to a CPU architecture designed to take advantage of instruction level parallelism (ILP). The VLIW approach, on the other hand, executes operations in parallel based on a fixed schedule determined when programs are compiled. Since determining the order of execution of operations (including which operations can execute simultaneously) is handled by the compiler, the processor does not need the scheduling hardware that the three techniques described above require. As a result, VLIW CPUs offer significant computational power with less hardware complexity (but greater compiler complexity) than is associated with most superscalar CPUs.
Comparison of cisc,risc and vliw

Source: http://www.site.uottawa.ca/~mbolic/elg6158/vliw1.ppt
The VLIW architecture is generalized from two well-established concepts: Horizontal micro coding and superscalar processing. A typical VLIW (very long instruction word) machine has instruction words hundreds of bits in length. As illustrated in the Figure-1, multiple functional units are used concurrently in a VLIW processor. All functional units share the use of a common large register file. The operations to be simultaneously executed by the functional units are synchronized in VLIW instruction, say, 256 or 1024 bits per instruction word, as implemented in the Multiflow computer models.

Fig-1, A typical VLIW processor and instruction format
Source: http://www.csbdu.in/virtual/DIGITAL%20MUP/5.3.php
Different fields of the long instruction word carry the opcodes to be dispatched to different functional units. Programs written in conventional short instruction words must be compacted together to form VLIW instructions and code compaction must be done by compiler .
Sources: Advanced computer architecture by Kai hwang
http://en.wikipedia.org/wiki/Very_long_instruction_word
http://www.csbdu.in/virtual/DIGITAL%20MUP/5.3.php
http://www.site.uottawa.ca/~mbolic/elg6158/vliw1.ppt
By- Tarun Kumar