CONCURRENT ACCESS
Concurrent computing is a form of computing in which several computations are executing during overlapping time periods – concurrently – instead of sequentially (one completing before the next starts). This is a property of a system – this may be an individual program, a computer, or a network – and there is a separate execution point or "thread of control" for each computation ("process"). A concurrent system is one where a computation can make progress without waiting for all other computations to complete – where more than one computation can make progress at "the same time".
The ability to gain admittance to a system or component by more than one user or process. For example, concurrent access to a computer means multiple users are interacting with the system simultaneously.
the lower 4 order bits are used to select memory modules while the higher order bits are used to select the address of the modules.
for eg: if we select 1st module and 1st address the equivalent would be 0001 0001 which equals 17.
if we select 2nd module and 1st address the equivalent would be 0001 0010 which equals 18
References: Wikipedia
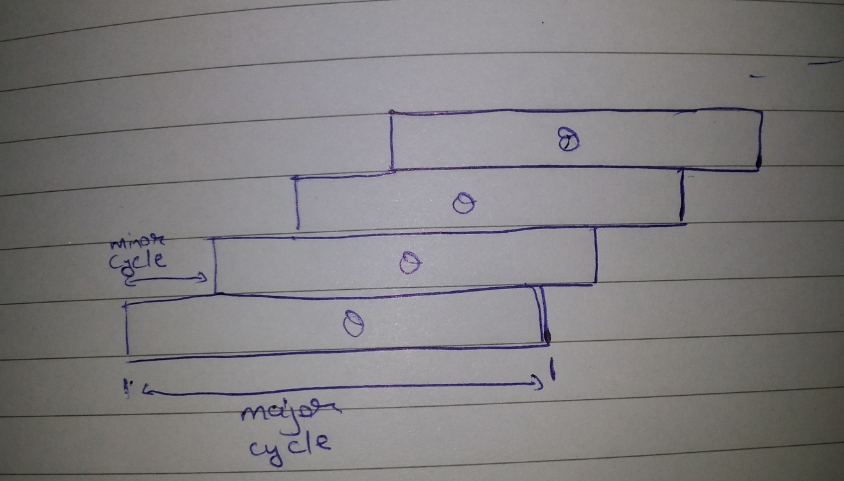
Ɵ = time taken by one major cycle
m = no of modules
n = length of vector
Ɵ/m = time taken by one stage of pipeline
Ɵ/m(m+n-1) = total time
Ɵ/m(m+n-1)(1/n) = average time
= Ɵ/m((m-1)/n+1))
So, when n->
when n=m, total time = 2Ɵ
Also, we haven't considered the time taken by instruction calling. Hence the bandwidth becomes ¼.
new average time = 4 Ɵ/m
IMPLEMENTATION
A number of different methods can be used to implement concurrent programs, such as implementing each computational execution as an operating system process, or implementing the computational processes as a set of threads within a single operating system process.
SEQUENTIAL ACCESS
In computer science, sequential access means that a group of elements (such as data in a memory array or a disk file or on magnetic tape data storage) is accessed in a predetermined, ordered sequence. Sequential access is sometimes the only way of accessing the data, for example if it is on a tape. It may also be the access method of choice, for example if all that is wanted is to process a sequence of data elements in order.
STRIP MINING
When a vector has a length greater than that of vector registers, segmentation of the long vector into fixed length segments is necessary. This technique has been called strip- mining. One vector segment is processed at a time. In case of Cray computers, the vector segment length is 64 elements.
Until all the vector elements in each segments are processed, the vector register cannot be assigned to another vector operation. Strip mining is restricted by the number of available vector registers and so is vector chaining.
References: Kai Hwong
SUBMITTED BY:
Shubham Gupta 336/CO/11
Siddhant Sanjeev 337/CO/11
Correction :- For 1st module and 1st location, address bits would be "00000000" and for 1st module 2nd location, it would be 00010000 i.e. 16 and for 2nd module 2nd location, it is 00010001 which is 17. So, this way each module can be accessed at a faster rate by switching the lower bits fast.
ReplyDelete"Also, we haven't considered the time taken by instruction calling. Hence the bandwidth becomes ¼."
ReplyDeleteCan somebody explain this? How does the BW become 1/4?
Let us take a case where there are 64 interleaved memory modules for a single vector processor, giving the possibility of 64 pieces of data accessed per major memory cycle.
DeleteThe main reason why this available bandwidth cannot be fully utilized is due to the peculiarities of application programs themselves.
1. Scalar data appear in between vector data in a random fashion. Even vector data may mot be exact multiples of 64.
2. In case of instructions, incorrectly predicted conditional branches can result in wastage of memory cycles. ( Instructions are not normally interspersed with data though).
3. In case the memory is shared with other processors, then conflicts can further reduce memory bandwidth.
Well, the stated reduction factor of 1/4 is just a rough estimate. Obviously it would depend upon the program. There is a Hellerman estimate which says B = degree-of-interleaving^0.56 (approx square root).
Improve memory utilization by means of strip mining. Strip mining, also known as loop sectioning, is a loop-transformation technique for enabling SIMD-encodings of loops, as well as providing a means of improving memory performanceFirst introduced for vectorizers, this technique consists of the generation of code when each vector operation is done for a size less than or equal to the maximum vector length on a given vector machine.
ReplyDeletereference:
http://software.intel.com/en-us/articles/how-to-use-strip-mining-to-optimize-memory-use-on-32-bit-intel-architecture
reference: http://en.m.wikipedia.org/wiki/Loop_tiling
ReplyDeleteLoop tiling , also known
as loop blocking , or strip mine and
interchange , is a loop optimization technique
used by compilers to make the execution of
certain types of loops more efficient.
Loop tiling partitions a loop's iteration space
into smaller chunks or blocks, so as to help
ensure data used in a loop stays in the cache
until it is reused. The partitioning of loop
iteration space leads to partitioning of large
array into smaller blocks, thus fitting accessed
array elements into cache size, enhancing
cache reuse and eliminating cache size
requirements.