28/03/2014
VECTOR PROCESSING (CONT.)
MEMORY: -
MORE MEMORY GIVES MORE POWER TO SYSTEM AND USER.
THE SYSTEM CAN DO MORE WORK, CAN OPERATE ON LARGER DATA.
MORE MEMORY - > MORE PARALLEL PROCESSING - > MORE DATA CAN FLOW IN
FOR THIS
1) MEMORY ORGANISATION IS NEEDED (FOR EX. IN VECTOR PROCESSING BY INCREASING BANDWIDTH).
2) DATA PLACEMENT IN MEMORY (FOR EX. IN MATRIX MULTIPLICATION ON 4D CUBE – DATA PLACEMENT IS IMPORTANT)
MASKING: -
IF SOME PROCESSORS ARE NOT REQUIRED, MASKING IS DONE SO THAT THOSE PROCESSORS REMAIN INACTIVE. THIS CAN PROVIDE BETTER PERFORMANCE IN SOME CASES.
EXAMPLE:
AN AFFINITY MASK IS A BIT MASK INDICATING WHAT PROCESSOR(S) A THREAD OR PROCESS SHOULD BE RUN ON BY THE SCHEDULER OF AN OPERATING SYSTEM. UNDER WINDOWS THERE ARE SEVERAL SYSTEM PROCESSES (ESPECIALLY ON DOMAIN CONTROLLERS) THAT ARE RESTRICTED TO THE FIRST CPU / CORE. SO, SETTING THE AFFINITY MASK FOR CERTAIN PROCESSES EXCLUDING THE FIRST CPU MIGHT LEAD TO BETTER APPLICATION PERFORMANCE.
IN PREFIX COMPUTATION, NUMBER OF REQUIRED PROCESSORS IN EACH STEP DECREASE. SO SOME PROCESSORS ARE REQUIRED TO BE MASKED.
IN CASE OF SPARSE MATRIX, ALL VALUES ARE NOT REQUIRED TO BE LOADED. THIS CAN BE USED TO IMPROVE EFFICIENCY.
THIS CAN BE DONE BY USING A COMBINATION OF ‘GATHER ‘AND ‘SCATTER ‘.
IF X IS THE SPARSE VECTOR, Y IS THE DENSE MATRIX AND INDEX IS A VECTOR THAT
STORES THE LOCATION OF NON-ZERO VALUES IN Y, THEN
GATHER –: ASSIGNS X [i] = Y [INDEX [i]]
SCATTER –: ASSIGNS Y [INDEX [i]] = X [i]
(NOTE : THE NOTATIONS FOR X AND Y MIGHT BE CONFUSING. THE CONDENSED VECTOR X IS CALLED AS THE SPARSE VECTOR WHILE THE MATRIX Y WHICH HAS A VAST MAJORITY OF ZERO VALUES IS CALLED AS THE DENSE VECTOR OR MATRIX. BEATS ME!!!)
VECTOR PROCESSORS HAVE HARDWARE SUPPORT FOR GATHER-SCATTER OPERATIONS, PROVIDING INSTRUCTIONS SUCH AS LOAD VECTOR INDEXED FOR GATHER AND STORE VECTOR INDEXED FOR SCATTER.
NOTE:
ISA SHOULD BE SIMPLE. COMPLEX INSTRUCTIONS DIRECTLY IMPLY WASTAGE OF SPACE.
ISA SHOULD NOT BE CHANGED TO INCLUDE COMPLEX INSTRUCTIONS THAT WILL BE RARELY USED. EXAMPLE: IT WOULD NOT MAKE SENSE TO CHANGE THE ISA FOR A NORMAL PROCESSOR TO INCLUDE GATHER AND SCATTER INSTRUCTIONS THAT WILL BE USED ONCE IN A BLUE MOON (MAAM’S WORDS).
USING MORE CACHE, REGISTERS, PIPELINING AND REMOVING COMPLEX INSTRUCTIONS REMOVES COMPLEX HARDWARE.
HARDWARE CATERING TO SUCH COMPLEX INSTRUCTIONS IS USED RARELY. GIVING SPACE TO MEMORY ON SILICON IS A BETTER OPTION.
FOR EXAMPLE : R [1: N] = (V1 [1: N] + S) * V2
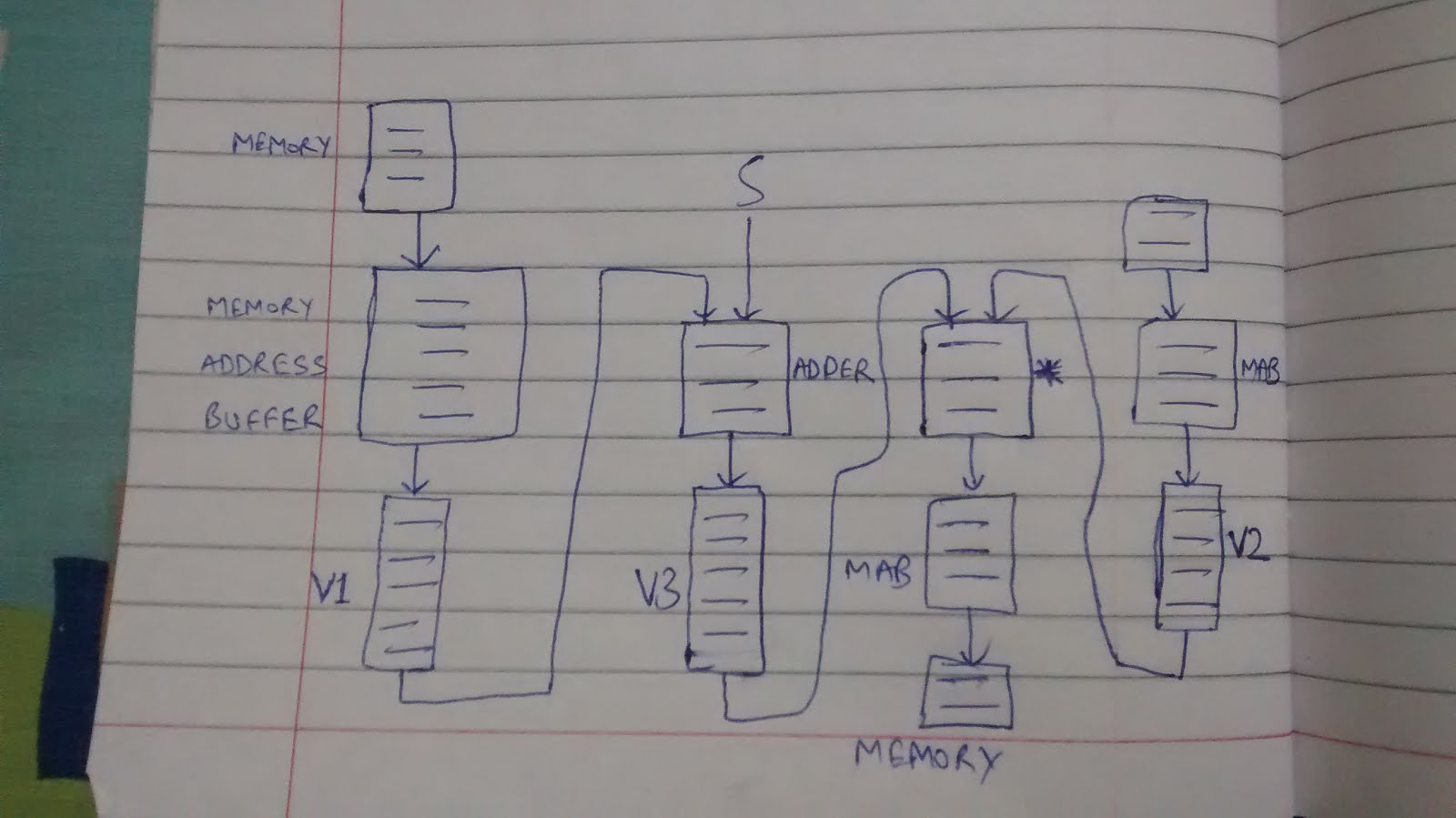
AS SHOWN ABOVE METHOD IS COSTLY.
TO IMPROVE COMPILER AND HARDWARE MUST WORK TOGETHER ON PROBLEM STATEMENT.
THE SAME WORK CAN BE DONE WITH LESS PROGRAMMABLE REGISTERS. SO IF COMPILER WORKS ALONG AND HARDWARE HAS SPECIAL FEATURES V3 WILL NOT BE REQUIRED.
IF SUCH A VECTORISATION COMPILER IS NOT USED, A COSTLY ARCHITECTURE IS REQUIRED AND A PROGRAMMER WILL BE REQUIRED WHO CAN THINK PARALLELY (HIGH PAY).
VECTORISING PROGRAM:-
do i1 = x1,y1
do i2 = x2,y2
.
.
S1 = A f1 (i1, i2… in)… fm (i1, i2… in)
n – Iterations
m – Dimensions
USUALLY, n = m
SUPPOSINGLY
A f1 (i1, i2… in)… fm (i1, i2… in) = B (g1, g2, g3…, gm)
NOW TAKING AN EXAMPLE
do i = 1 to 10
A i = A i-1
THIS RESULTS IN SOMETHING LIKE A1 = A0; A2 = A1; A3 = A2 AND SO ON.
THUS WE CAN SEE THERE IS A FLOW DEPENDENCY BECAUSE A DATA VARIABLE REFERRED ON LHS IS REFERRED ON RHS AT SOME OTHER TIME.
WE CAN REPRESENT THIS IN ITERATION SPACE.
A F1(X) = B G1(Y)
X = ITERATION VECTOR (LEXICOGRAPHIC ORDER)
G(X) , F(X) = FUNCTIONS OF ITERATION VECTOR
A F(X) = DATA
Yi – Xi = DISTANCE VECTOR FOR EVERY DIMENSION
3 CASES POSSIBLE:
1) Xi < Yi
2) Xi > Yi
3) Xi = Yi
COMPILER NEEDS TO ADDRESS TO SUCH AN ISSUE.
SUBMITTED BY :
SIDHANT JAIN ( 339/CO/11)
SIKANDER MAHAN ( 340/CO/11)