Shared Memory
Shared memory is memory that may be simultaneously accessed by multiple programs with an intent to provide communication among them or avoid redundant copies.
Shared memory is extensively used for inter process communication (IPC), i.e. a way of exchanging data between two programs running at the same time.One process creates an area in RAM which other processes can access.
Shared memory is the fastest form of IPC since data does not need to be copied between communication processes Often, semaphores are used to synchronize shared memory access.
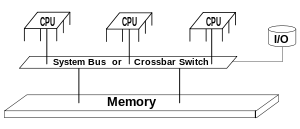
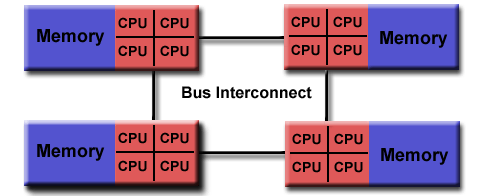
Shared memory machines have been classified as UMA and NUMA, based upon memory access times.
Shared Memory (UMA)

Shared Memory (NUMA)
Shared Memory is an efficient means of passing data between programs. One program will create a memory portion, which other processes (if permitted) can access. A shared memory segment is described by a control structure with a unique ID that points to an area of physical memory
Shared memory is a feature supported by UNIX System V, including Linux, SunOS and Solaris. One process must explicitly ask for an area, using a key, to be shared by other processes. This process will be called the server. All other processes, the clients that know the shared area can access it.
A shared memory segment is identified by a unique integer, the shared memory ID.
A process creates a shared memory segment using shmget()|. The original owner of a shared memory segment can assign ownership to another user with shmctl(). It can also revoke this assignment. Other processes with proper permission can perform various control functions on the shared memory segment using shmctl(). Once created, a shared segment can be attached to a process address space using shmat(). It can be detached using shmdt() (see shmop()). The attaching process must have the appropriate permissions for shmat(). Once attached, the process can read or write to the segment, as allowed by the permission requested in the attach operation. A shared segment can be attached multiple times by the same process. A shared memory segment is described by a control structure with a unique ID that points to an area of physical memory. The identifier of the segment is called the shmid. The structure definition for the shared memory segment control structures and prototypes can be found in <sys/shm.h>.
Parallel tasks share a global address space which they read and write to asynchronously, which requires protection mechanisms such as locks, semaphores and monitors to control concurrent access.
Advantages:
-
Global address space provides a user-friendly programming perspective to memory
Data sharing between tasks is both fast and uniform due to the proximity of memory to CPUs
Disadvantages:
Primary disadvantage is the lack of scalability between memory and CPUs. Adding more CPUs can geometrically increases traffic on the shared memory-CPU path, and for cache coherent systems, geometrically increase traffic associated with cache/memory management.
Programmer responsibility for synchronization constructs that ensure "correct" access of global memory.
Expense: it becomes increasingly difficult and expensive to design and produce shared memory machines with ever increasing numbers of processors.
IPC using Shared Memory
http://faculty.kfupm.edu.sa/ics/garout/Teaching/ICS431/Lab14.pdf
http://www.cs.cf.ac.uk/Dave/C/node27.html
Shared and distributed memory
http://www.slideshare.net/MrSMAk/lecture-6-12062242
Programming with Shared Memory
http://www.cs.nthu.edu.tw/~ychung/slides/para_programming/slides8.
Programs available at the following links
https://publib.boulder.ibm.com/infocenter/iseries/v5r3/index.jsp?topic=%2Fapis%2Fapiexusmem.htm
http://www.kohala.com/start/unpv22e/unpv22e.chap12.pdf
Message Passing Model
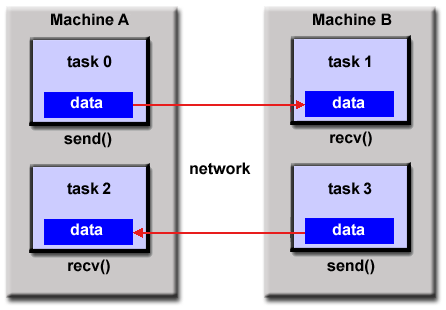
This model demonstrates the following characteristics:
A set of tasks that use their own local memory during computation. Multiple tasks can reside on the same physical machine and/or across an arbitrary number of machines.
Tasks exchange data through communications by sending and receiving messages.
Data transfer usually requires cooperative operations to be performed by each process. For example, a send operation must have a matching receive operation.
 Implementations:
Implementations:-
From a programming perspective, message passing implementations usually comprise a library of subroutines. Calls to these subroutines are embedded in source code. The programmer is responsible for determining all parallelism.
Since interactions are accomplished by sending and
receiving messages, the basic operations in the
message-passing programming paradigm are send and
receive.
• In their simplest form, the prototypes of these operations are defined as follows:
send(void *sendbuf, int nelems, int dest)
-
receive(void *recvbuf, int nelems, int source)
sendbuf points to a buffer that stores the data to be sent,
• recvbuf points to a buffer that stores the data to be received,
• nelems is the number of data units to be sent and received,
• dest is the identifier of the process that receives the data,
• source is the identifier of the process that sends the data.
Message Passing Interface (MPI)
https://computing.llnl.gov/tutorials/mpi/
Comparison of message passing and shared memory http://www.dauniv.ac.in/downloads/CArch_PPTs/CompArchCh12L12MsgPassingSharing.pdf
References:
http://en.wikipedia.org/wiki/Shared_memory
https://computing.llnl.gov/tutorials/parallel_comp/
http://siber.cankaya.edu.tr/ParallelComputing/week4/week4p.pdf
Submitted by
Somil Srivastava 341/CO/11
Sonam Kumari 343/CO/11
One of the practical use of shared memory paradigm:
ReplyDeletePARALLEL SPELL-CHECKING ALGORITHM Based on Yahoo! N-Grams
Dataset:
This paper proposes a new parallel shared-memory spell-checking algorithm that uses
rich real-world word statistics from Yahoo! N-Grams Dataset to correct non-word and real-word errors in computer text.
Link:
https://www.google.co.in/url?sa=t&rct=j&q=&esrc=s&source=web&cd=2&cad=rja&uact=8&ved=0CDwQFjAB&url=http%3A%2F%2Farxiv.org%2Fpdf%2F1204.0184&ei=4qo6U_zAPM6FrAeMt4CQCw&usg=AFQjCNH9M97lUO5aJj4tr0nHKHdv2FR1ag&sig2=a0LTAn2gwjUuPKq0ZLmlxg&bvm=bv.63934634,d.bmk
apart from UMA and NUMA types of shared memory architectures, i also found COMA on the internet. COMA( cache-only memory architecture). In this the local memories for the processors at a node is used as cache. This is in contrast to using the local memories as actual main memory, as in NUMA organizations.
ReplyDeleteIn NUMA, each address in the global address space is typically assigned a fixed home node. When processors access some data, a copy is made in their local cache, but space remains allocated in the home node. Instead, with COMA, there is no home. An access from a remote node may cause that data to migrate. Compared to NUMA, this reduces the number of redundant copies and may allow more efficient use of the memory resources. On the other hand, it raises problems of how to find a particular data (there is no longer a home node) and what to do if a local memory fills up (migrating some data into the local memory then needs to evict some other data, which doesn't have a home to go to). Hardware memory coherence mechanisms are typically used to implement the migration.
source: wikipedia
All students:
ReplyDelete1. Please write your posts in your own words. I find long sections simply copy pasted from some source, which is totally unacceptable.
2. Any material that is copy pasted must be cited. An example is:
In this the local memories for the processors at a node is used as cache. This is in contrast to using the local memories as actual main memory, as in NUMA organizations [1].
[1]"Cache only memory architecture", In Wikipedia, Retrieved 3 April, 2014 from http://en.wikipedia.org/wiki/Cache-only_memory_architecture.
3. Wiki articles are not the primary source of the knowledge expanded upon in article pages. Often the contents are not accurate too. You may go through some of the references mentioned after a wiki article, enhance your knowledge and quote them instead.
4. It is important to express in your own words. For this, write some notes while you read through the article. Nevertheless, the original source of knowledge must be cited.