VERY LONG INSTRUCTION WORD (VLIW) ARCHITECTURE
VLIW refers to a processor architecture designed to take advantage of instruction level parallelisation. The VLIW approach executes operations in parallel based on a fixed schedule determined when programs are compiled. Since determining the order of execution of operations is handled by the compiler, the processor does not need the scheduling hardware. As a result, VLIW CPUs offer significant computational power with less hardware complexity.
This type of processor architecture is intended to allow higher performance without the inherent complexity of some other approaches. In VLIW loop unrolling gives an opportunity to parallelize unlooped portion of the code more.
TRACE SCHEDULING
TRACE SCHEDULING is an optimization technique used in compilers for computer programs. Trace scheduling was originally developed for Very Long Instruction Word, or VLIW machines, and is a form of global code motion. It works by converting a loop to long straight-line code sequence using loop unrolling and static branch prediction.
An important factor before trace scheduling is that it is necessary to perform profiling( varying data and recording observations) for the scheduling.
Trace Scheduling is primarily done in 2 steps:
1) Trace selection : Find likely sequence of basic blocks of long sequence of straight line codes.
2) Trace Compaction: - Squeeze trace into few VLIW instructions.
- Need instruction to UNDO code incase prediction goes wrong.
EXAMPLE
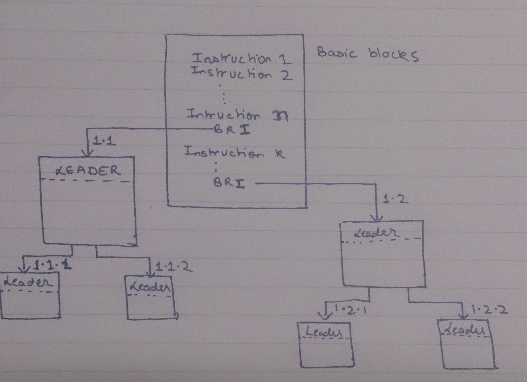
The above mechanism can be depicted in the form of a graph.
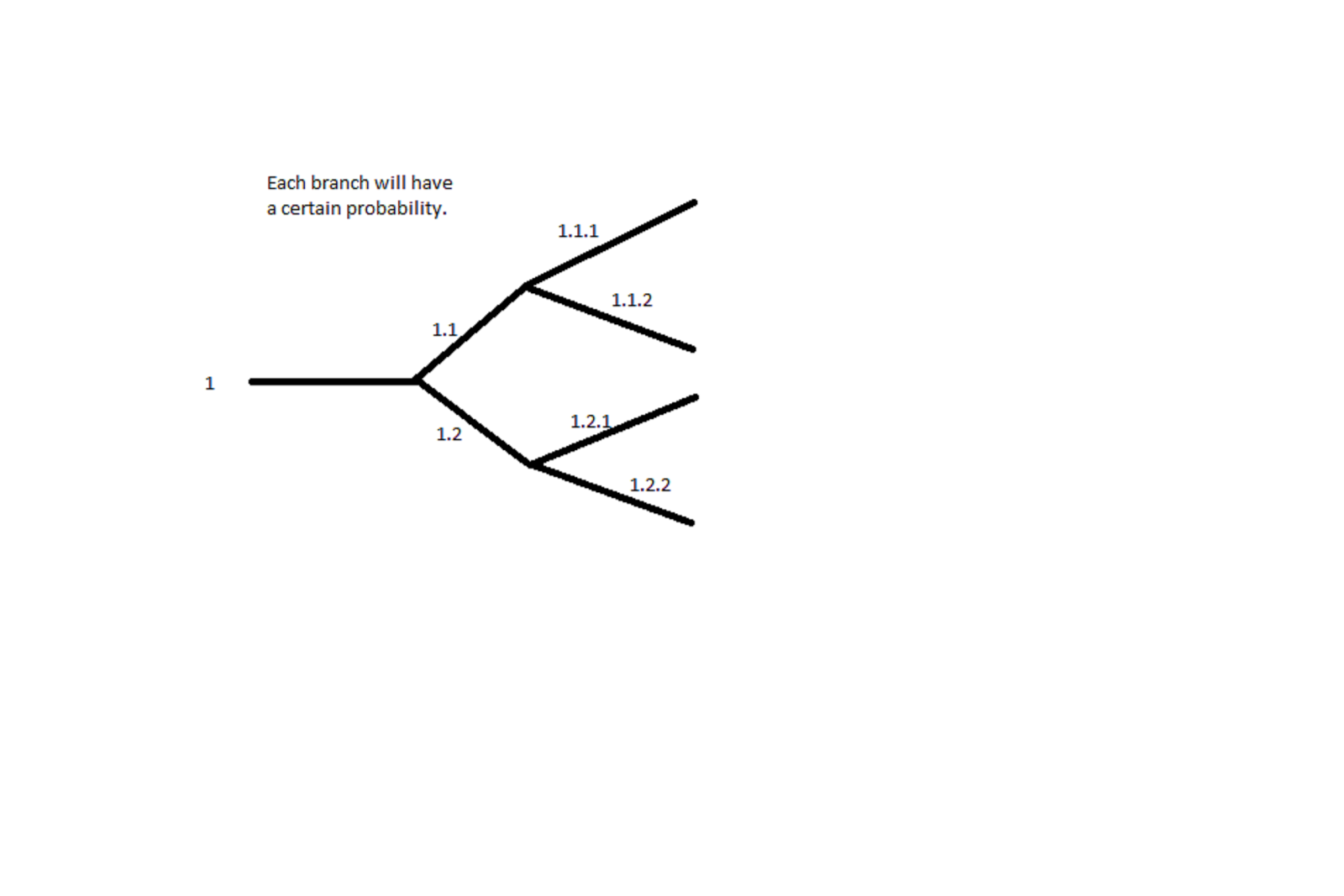
Here each edge represents a block and each node represents a leader.
An important feature of Trace scheduling is that the cache for macro-instructions follows SPATIAL LOCALITY whereas trace cache follows TEMPORAL LOCALITY.
Disadvantages of Trace scheduling:
1) CODE EXPANSION: The UNDO codes are instructions introduced by the compiler to undo certain instructions in case the the trace path is not followed. This results in code expansion.
Optimization of the most probable path results in inefficiency in the lesser probable paths and resulting in the upward (if some instructions are added in between) or downward(in case of removal of some instructions) motion of code.
2) BACKWARD COMPATIBILITY: Backward compatibility is not possible as width of the ROM cannot be changed.
However in microprogrammed CU's the ROM is within them hence allowing backward compatibility.
3) COMPILING TIME: The increased number of instructions because of the 'undo' code results in an increased compiling time of a program.
STATIC AND DYNAMIC SCHEDULING
STATIC SCHEDULING
Static scheduling is entirely performed by the compiler. The processor, in this case, receives dependence-free and optimized code for parallel execution. Static scheduling minimize the number of hazards and stalls.
Static scheduling is mostly used in VLIW architecture and few other pipelined architecture.
DYNAMIC SCHEDULING
Dynamic scheduling does not have parallel code optimization. It is done entirely by the processor. The processor detects and resolves dependencies on its own. Code for one pipeline runs well on another pipeline.
Often Dynamic Scheduling is boosted by static parallel code optimization via optimization techniques like loop unrolling. Its is performed by the processor in conjunction with the parallel optimizing compiler.
A major limitation of the pipelining techniques is that they use in-order instruction issue: if an instruction is stalled in the pipeline, no later instructions can proceed. Thus, if there is a dependency between two closely spaced instructions in the pipeline, it will stall. For example:
| DIVD | F0, F2, F4 |
ADDD | F10, F0, F8 |
SUBD | F12, F8, F14 |
SUBD instruction cannot execute because the dependency of ADDD on DIVD causes the pipeline to stall; yet SUBD is not data dependent on anything in the pipeline. This is a performance limitation that can be eliminated by not requiring instructions to execute in order.
To allow SUBD to begin executing, we must separate the instruction issue process into two parts: checking the structural hazards and waiting for the absence of a data hazard. We can still check for structural hazards when we issue the instruction; thus, we still use in order instruction issue. However, we want the instructions to begin execution as soon as their data operands are available. Thus, the pipeline will do out-of-order execution, which implies out-of-order completion.
By-
Vaibhav Bhatnagar and Varun Singla
No comments:
Post a Comment